Introducing Gemma 3n: Google's Revolutionary Mobile-First Multimodal AI

Google just released Gemma 3n, and it's genuinely changing the game for mobile AI development. This might be the most practical AI release we've seen this year.
Here's what makes it special: powerful multimodal AI that runs entirely on your device—no cloud, no API bills, no privacy concerns. Your laptop, phone, even that MacBook Air gathering dust can run these models locally.
What is Gemma 3n?
Gemma 3n is Google's new family of open-source AI models designed specifically for on-device deployment. Unlike traditional models that require cloud infrastructure, these are engineered to run efficiently on consumer hardware while delivering impressive performance across text, image, audio, and video tasks.
The model comes in two sizes:
- E2B (2B effective parameters): ~2GB memory footprint, optimized for speed
- E4B (4B effective parameters): ~3GB memory footprint, higher capability
What's particularly clever is the nested architecture—the 4B model literally contains the complete 2B model inside it. Download once, get both sizes.
Performance That Actually Matters
Benchmarks are one thing, but real-world performance is what counts. The E4B model achieved an LMArena score over 1300, making it the first model under 10 billion parameters to reach this milestone.
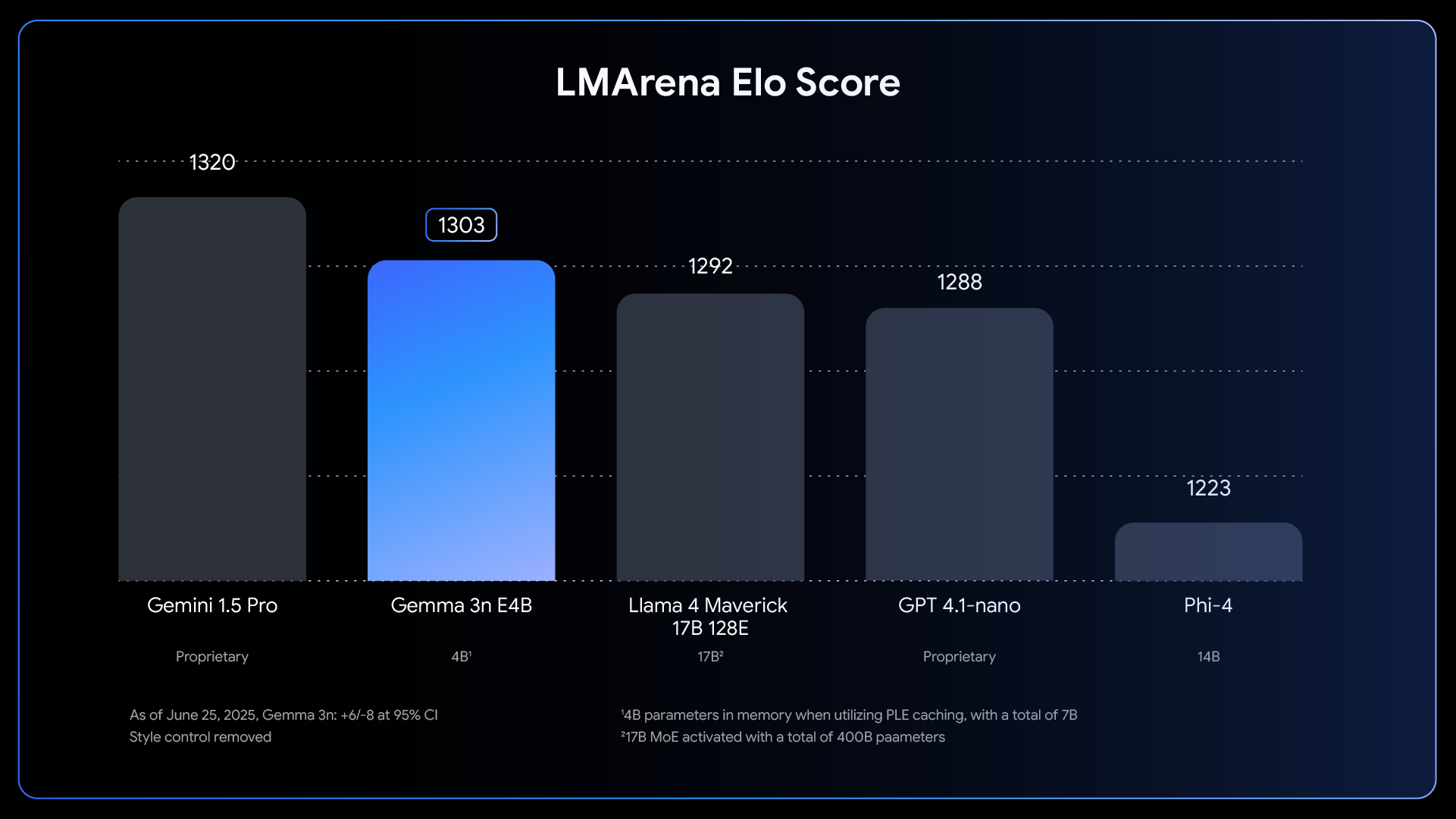
LMArena Elo scores showing Gemma 3n E4B's competitive performance
According to Google's benchmarks and early community reports, the models deliver impressive performance on consumer hardware. The speed will vary based on your device specifications, but the models are optimized for real-time inference on mobile and laptop hardware.
The Technical Innovation
Three key innovations make Gemma 3n special:
1. MatFormer Architecture
Think Russian nesting dolls. The MatFormer (Matryoshka Transformer) architecture allows a larger model to contain smaller, fully functional versions. This means you can extract custom model sizes between 2B and 4B parameters using their "Mix-n-Match" technique.
2. Per-Layer Embeddings (PLE)
This is the memory efficiency breakthrough. While the models have 5B and 8B total parameters respectively, PLE allows significant portions to run on CPU while keeping only the core transformer weights (~2B for E2B, ~4B for E4B) in your GPU's VRAM.
3. Enhanced Multimodal Capabilities
Gemma 3n includes new audio encoders based on Universal Speech Model (USM) and MobileNet-V5 for vision—both optimized for mobile deployment. The vision encoder processes up to 60 FPS on a Google Pixel, enabling real-time video analysis.
Google's Introduction Video
Getting Started
Setting up Gemma 3n is surprisingly straightforward. Here are your options:
Quick Test (No Setup Required)
Try it immediately at Google AI Studio.
Local Installation with Ollama
For local deployment, Ollama provides the easiest path:
# Install Ollama
curl -fsSL https://ollama.ai/install.sh | sh
# Download Gemma 3n models
ollama run gemma3n:e2b # Effective 2B model (~5.6GB download)
ollama run gemma3n:e4b # Effective 4B model (~7.5GB download)Core Capabilities
According to Google's documentation, Gemma 3n is designed for multimodal applications with the following key capabilities:
Multimodal Understanding
- Text processing - Enhanced quality across multilinguality (140 languages), math, coding, and reasoning
- Image analysis - MobileNet-V5 vision encoder supports multiple resolutions and real-time processing
- Audio processing - Automatic Speech Recognition (ASR) and translation, particularly strong for English, Spanish, French, Italian, and Portuguese
- Video understanding - Capable of processing video inputs (up to 60 FPS on Google Pixel)
Intended Use Cases
Google specifically mentions these applications:
- Content Creation - Text generation, chatbots, summarization
- Data Extraction - Image and audio data interpretation
- Research and Education - NLP research, language learning tools
- On-device Applications - Privacy-focused mobile and desktop apps
Why This Matters for Developers
The economics of local AI change everything:
- Zero marginal cost per inference after setup
- No rate limits to constrain your applications
- Complete privacy - data never leaves your device
- No vendor lock-in - you control the entire stack
For indie developers and startups, this removes the fear of success becoming expensive. Build AI features without worrying about viral usage destroying your budget.
The Road Ahead
Google is working on "elastic execution" - a single deployed model that dynamically switches between E2B and E4B inference based on task complexity and device load. We're also likely to see:
- Smaller 1B variants for ultra-low-power devices
- Better mobile optimization for iOS and Android
- Specialized domain-specific versions
Bottom Line
Gemma 3n represents a significant step toward practical, accessible AI. It's not the most powerful model available, but it's probably the most useful for real-world applications where privacy, cost, and reliability matter.
The combination of competitive performance, multimodal capabilities, and true local deployment makes this a compelling choice for developers building the next generation of AI-powered applications.
If you've been waiting for the right moment to dive into local AI development, this might be it. The model weights are free, the licensing is commercial-friendly, and the ecosystem support is already impressive.
What will you build with it?
You might also like

